
On this page
If you are impatient (like me) and would like to try assembly right away - go to the tutorial.
Perhaps assembly is spelled assembly for a reason - it is complicated. When I first needed to perform assembly I was uneasy about it - I had never done it before. What I needed was to sequence a genome of an E. coli type C-1 that my lab was using in experimental evolution experiments (e.g., Dickins 2009). We had generated data and were sitting figuring out what to do with it. Here I describe our logic and how we ended up with integrating genome assembly into Galaxy, so you can use your time more wisely.
Getting data
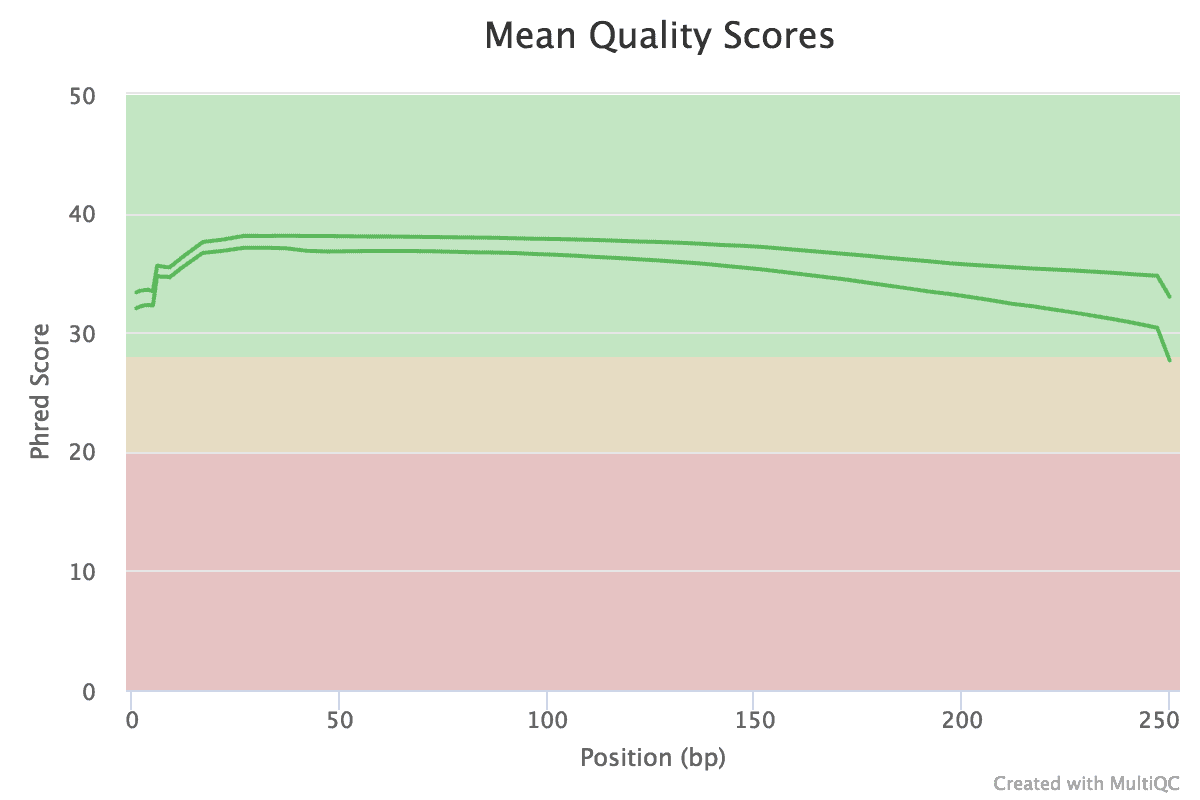
We have sequenced the genome using two technologies: Illumina MiSeq (250 nucleotide paired reads) and Oxford Nanopore. For MiSeq we used Penn State core facility while Oxford Nanopore Sequencing was performed in James Taylor’s lab who just could not resist and bought the MinIon device. Of course devices don’t simply sequence the DNA. Libraries need to be prepared, QCed, and sequenced. Both myself and James are lucky to have excellent people in the lab. For MiSeq run all experimental work was performed by Han Mei, a graduate student at Penn State. For Oxford Nanopore run everything was done by Mallory Freeberg (currently a bioinformatician at EMBL-EBI). As you can see below the data were spectacular:

Trying assembly
After reading and consulting with people who actually understand genome assembly process (notably Paul Medvedev) we chose SPAdes for performing the assembly. SPAdes supports hybrid assembly where short high quality reads (Illumina in our case) are supplemented by long, relatively inaccurate reads (Oxford Nanopore that we’ve generated).
Running SPAdes
We installed Spades 3.11.1 using Bioconda and generated assembly using the following command:
spades.py -k 21,33,55,77,99,127 -1 forward_miseq_reads.fastq -2 reverse_miseq_reads.fastq --nanopore nanopore_reads.fastq -t 20 -o assembly It produced the following assembly (for distinction between contigs and scaffolds see here):
| Statistics | Contigs | Scaffolds |
|---|---|---|
| # contigs/scaffolds > 0 bp | 2,271 | 2,253 |
| # contigs/scaffolds ⋝ 1,000 bp | 22 | 33 |
| Total length > 0 bp | 5,676,639 | 5,679,836 |
| Total length ⋝ 1000 bp | 4,611,915 | 4,629,934 |
| Largest contig/scaffold | 4,135,925 | 4,575,240 |
| GC (%) | 50.91 | 50.91 |
| N50 | 4,135,925 | 4,575,240 |
| N75 | 4,135,925 | 4,575,240 |
| # of Ns per 100 kbp | 0.0 | 22.07 |
Here you can see that the largest scaffold is 4,575,240 bp which is very close to a complete E. coli genome (E. coli K-12’s genome is 4,641,652 bp). But what about these extra 2,253 scaffolds? Looking at assembly graph generated with SPAdes using Bandage produces this image:

At the bottom of this graph there is a very large number of subgraphs disconnected from the main graph. It was not clear to me what to do with them and what is their significance.
Unicycler to the rescue
![]()
Ryan Wick, the author of Bandage used above, has written a tool, Unicycler, that is designed to produce a much more palatable assembly. Unicycler uses SPAdes to produce an assembly graph, which is then bridged (simplified) using long reads to produce longest possible set of contigs. These are then polished by aligning original short reads against produced contigs and feeding these alignment to Pilon - an assembly improvement tool.
Applying Unicycler to the same data produces just two (instead of 2,271!) contigs:
| Statistics | Contigs |
|---|---|
| # contigs/scaffolds > 0 bp | 2 |
| # contigs/scaffolds ⋝ 1,000 bp | 2 |
| Total length > 0 bp | 4,581,676 |
| Total length ⋝ 1000 bp | 4,581,676 |
| Largest contig | 4,576,290 |
| GC (%) | 50.93 |
| N50 | 4,576,290 |
| N75 | 4,576,290 |
| # of Ns per 100 kbp | 0.0 |
and the final assembly graph that looks like this:

The second short contig is simply the complete genome of bacteriophage ɸX174, which is added as spike-in in Illumina sequencing protocol.
So after doing all of this the obvious question is why not to enable assembly is Galaxy?
Assembly on the web
Unicycler has proven to be a great tool. So with help of Björn Grüning, Delphine Lariviere, and Dave Bouvier we added it to Bioconda and wrapped it for Galaxy, so anyone can repeat this entire analysis on-line without installing and configuring anything.

By allowing assembly tools in Galaxy we are also allowing multiple users to perform assembly simultaneously. This requires substantial computational resources. Execution of Unicycler on Galaxy main instance actually takes place on Bridges supercomputer at the Pittsburgh Supercomputing Center. This resource allocation is provided by a grant from the XSEDE consortium for which we are extremely grateful.
The Unicycler interface in Galaxy looks like this:

But it’s not just Unicycler, we’ve also integrated Quast to evaluate assembly quality and Prokka to produce annotations. So you can start with sequencing reads and end up with full-fledged annotated genome:
So …