GPU-enabled deep learning on Galaxy
Taking advantage of Galaxy's GPU computing nodes
The European Galaxy server relies on the compute nodes provided by the de.NBI-Cloud. Did you know that some of them are GPU-enabled?
Any Galaxy tools that require a GPU to function (e.g. instaGRAAL) will automatically be scheduled to run on a GPU node by our job router. However, there are tools that can take advantage of a GPU, although they run on a CPU by default. Galaxy lets you select the type of compute node where such tools should be sent.
Among those tools is “Deep learning training and evaluation”, which runs Keras under the hood. Under certain circumstances, the use of a GPU can accelerate the training. In fact, deep learning model architectures such as convolutional neural networks (CNNs) and feed-forward neural networks can be trained several times faster on GPUs, while for other model architectures such as recurrent neural networks (RNNs), the advantage is less significant as they have recurrent connections that are harder to parallelize.
To use a GPU for training deep learning models, go to the tool’s page and scroll down to the “Job Resource Parameters” section at the end of the tool’s definition. Choose “Specify job resource parameters” and then under “Use GPU resources” select “Yes”.
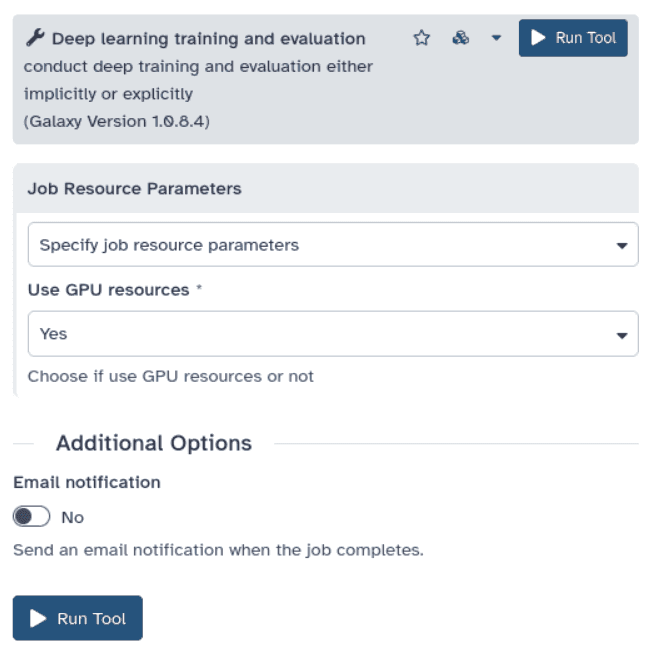
Are job resource selectors the right approach?
Job resource selectors allow fine-tuning the destination of a job based on the computing resources it needs. Indeed, it would be a waste of resources to keep a GPU-enabled computing node busy with jobs from tools that may take advantage of a GPU only under specific circumstances. But they have drawbacks: they put the burden of deciding the destination on the user and they reduce the portability of workflows.
In most situations, we would recommend Galaxy administrators to let the job router take this decision. For example, if it were possible to programatically detect the kind of computing node where the job should run, why not writing a rule that takes the decision? In addition, Galaxy administrators can take advantage of metascheduling to dynamically decide the destinaton based on the cluster load.
If despite that, as a Galaxy administrator you still find job resource selectors useful for your community and are interested in implementing this feature in your instance, visit the TPV job router tutorial on the Galaxy Training Network to learn how to add a job resource selector to a tool’s page. Additionally, for the GPU use-case you can take inspiration from UseGalaxy.eu’s implementation: check out our job_resource_params_conf.xml, job configuration file, list of configuration files, Galaxy configuration file, TPV tools configuration file and (within the latter file) the configuration to be applied to each tool.