Data Privacy in Galaxy
On this page
Premise
How is the server I’m working at configured?
On the public Galaxy Main server at https://usegalaxy.org, datasets are public but unlisted by default. End-users are in full control of specifying more privacy for their own data. Read below for how.
When working at a different Galaxy server, contact the administrators for clarification. Contact information is commonly found on the home page of a Galaxy server and/or included on known public Galaxy Server’s directory pages.
Basics
Galaxy provides means for users and administrators to set data privacy. The model allows permissions to be set on a fine-grained level, from completely private through a couple of users to entire collaborative groups.
Users may choose the default permissions that newly created datasets will acquire. These defaults apply to datasets acquired from outside of Galaxy, via sources such as the upload tool, UCSC, BioMart and EpiGRAPH. Datasets within Galaxy, such as those imported from a dataset library, or shared from another user retain the permissions set in the library or by the sharing user. Permissions on datasets created through running a tool are derived from the input datasets. More details on how permissions are set can be found below.
Key Operations
Following list contains the most important operations everybody should know with regards to dataset privacy.
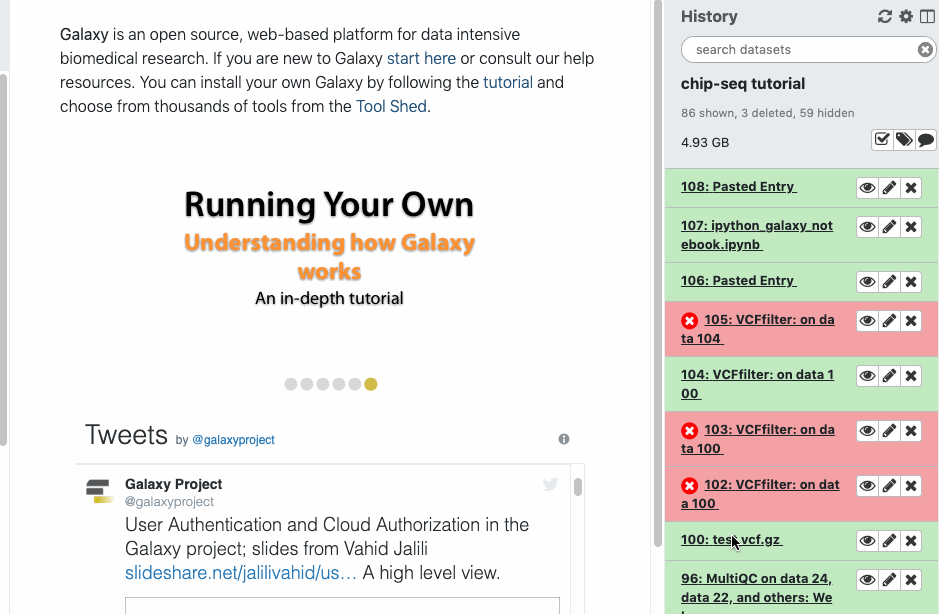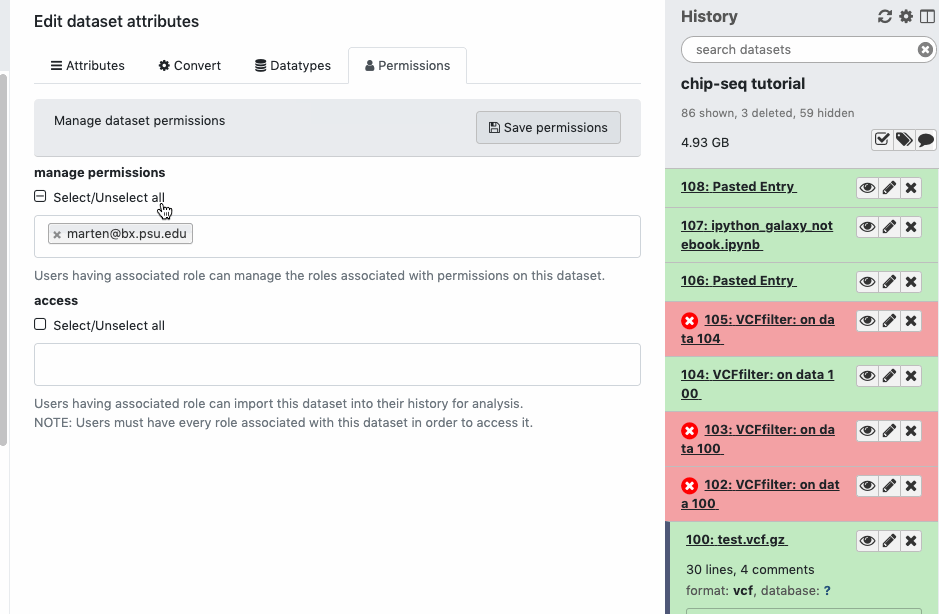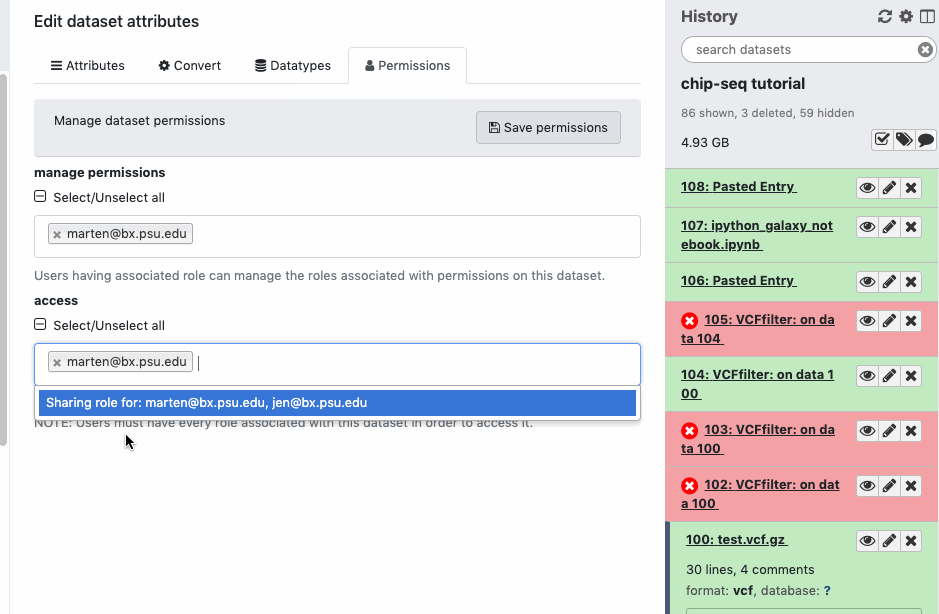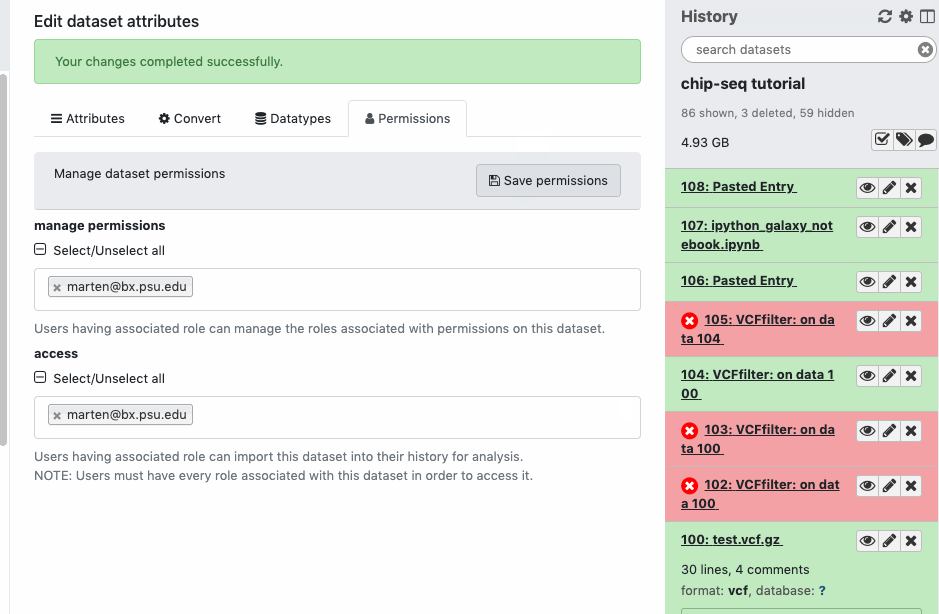
For datasets you have created (or were given permissions) you can control what roles can access it. The interface is available on history datasets after clicking the ‘pencil - Edit attributes’ icon and then moving on the ‘Permissions’ tab. Watch animation. Adding additional roles to the ‘access’ permission along with your “private role” does not do what you may expect. Since roles are always logically ANDed together, only you will be able to access the dataset, since only you are a member of your “private role”.
{kind=link}
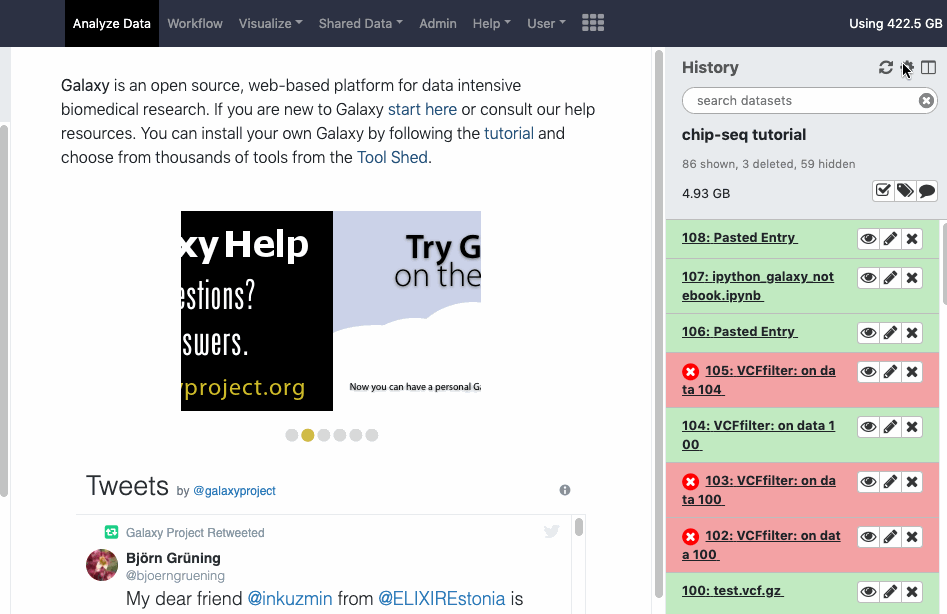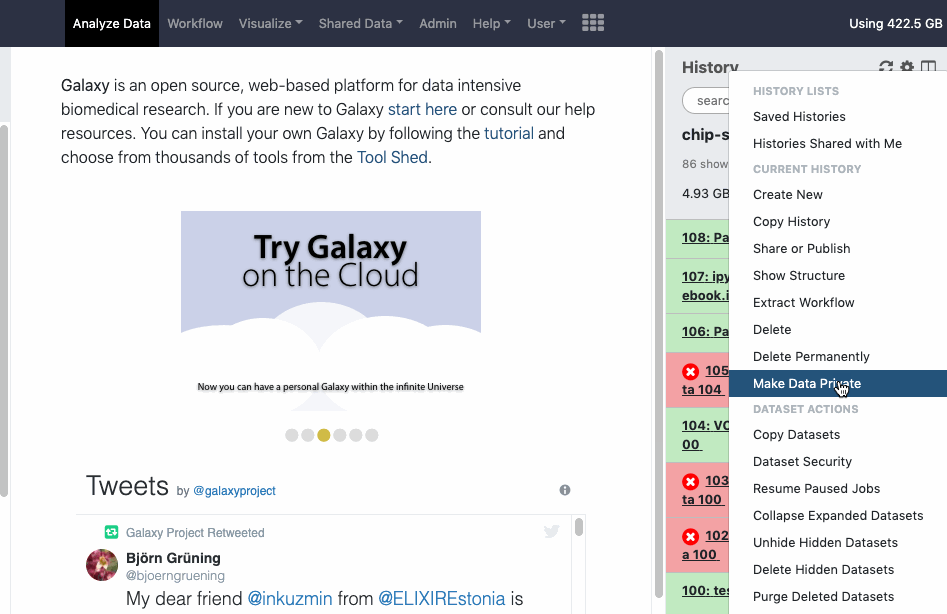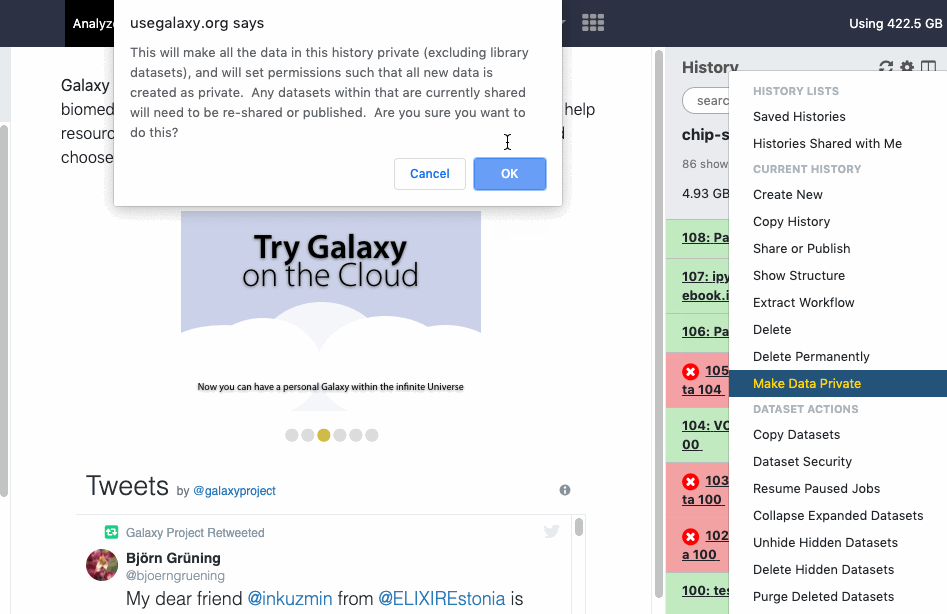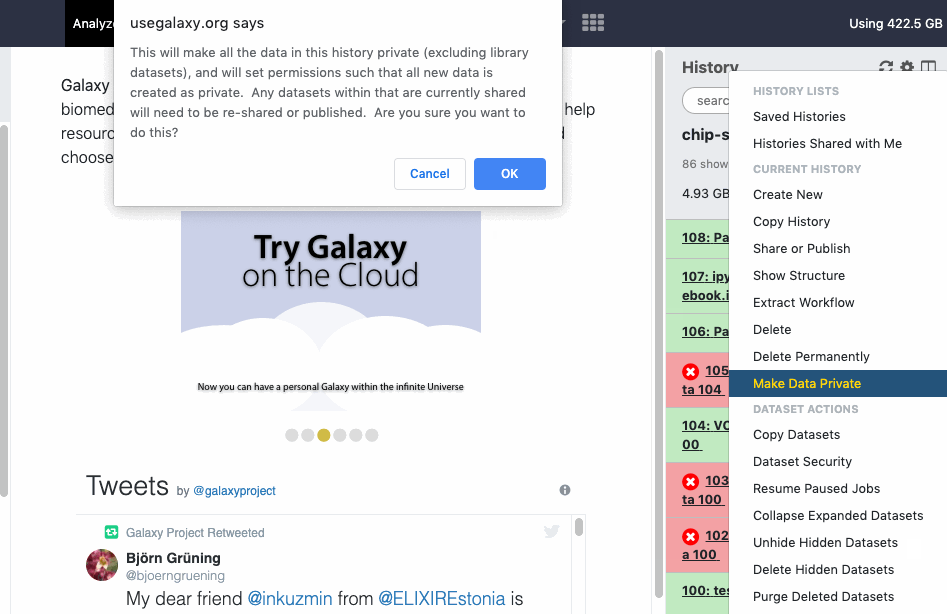
You can make all datasets in a given history private to you by choosing the ‘Make Data Private’ option in the dropdown menu available under the ‘cog - History options’ icon in the top of the history. Also sets the default settings for all new datasets in this history to private. Watch animation.
{kind=link}
Under the ‘cog - History options’ menu you can choose ‘Dataset Security’ and set the default permissions for all new datasets created in this history.
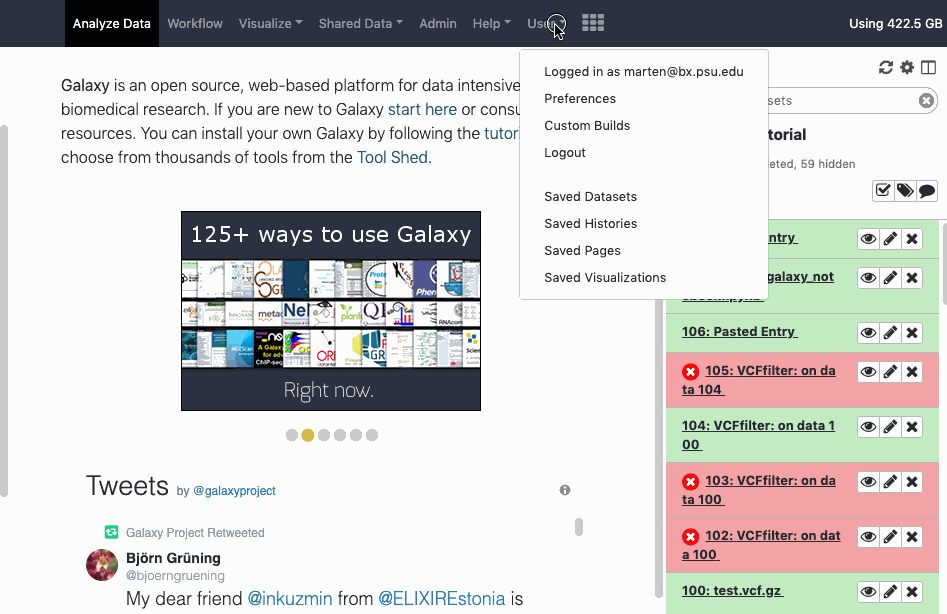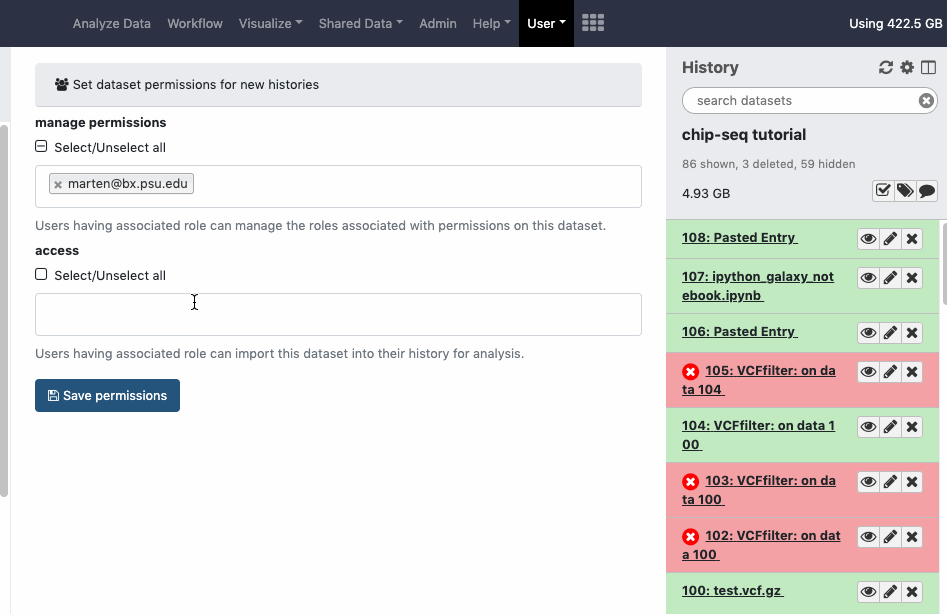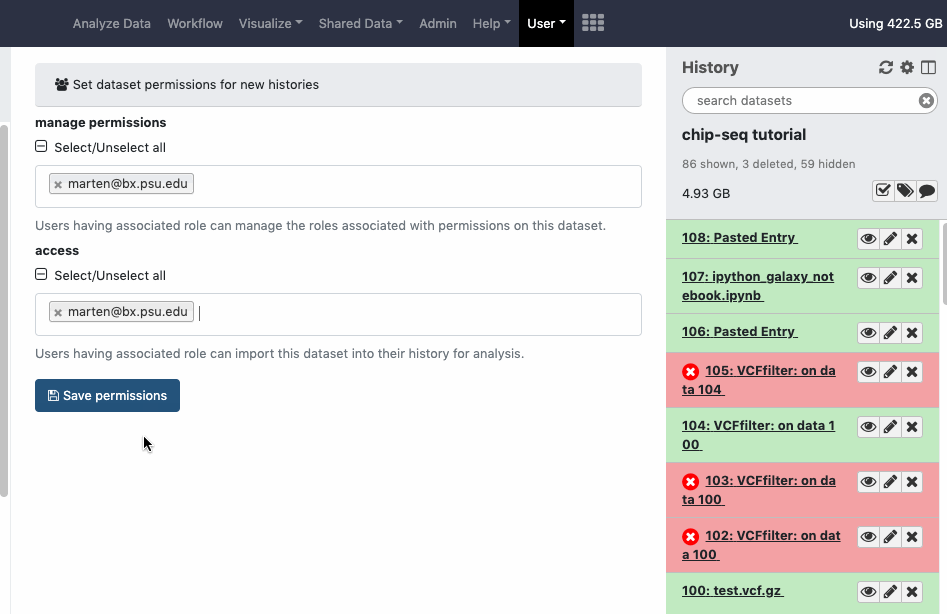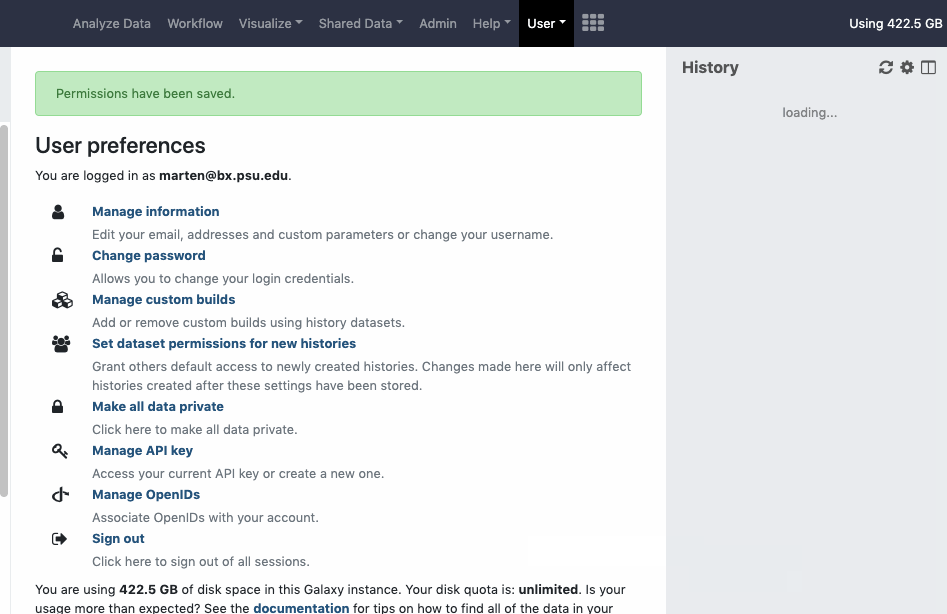
Under ‘User - Preferences’ you can find the ‘Set dataset permissions for new histories’ item which will allow you to set default privacy settings for contents of newly created histories. Watch animation.
{kind=link}
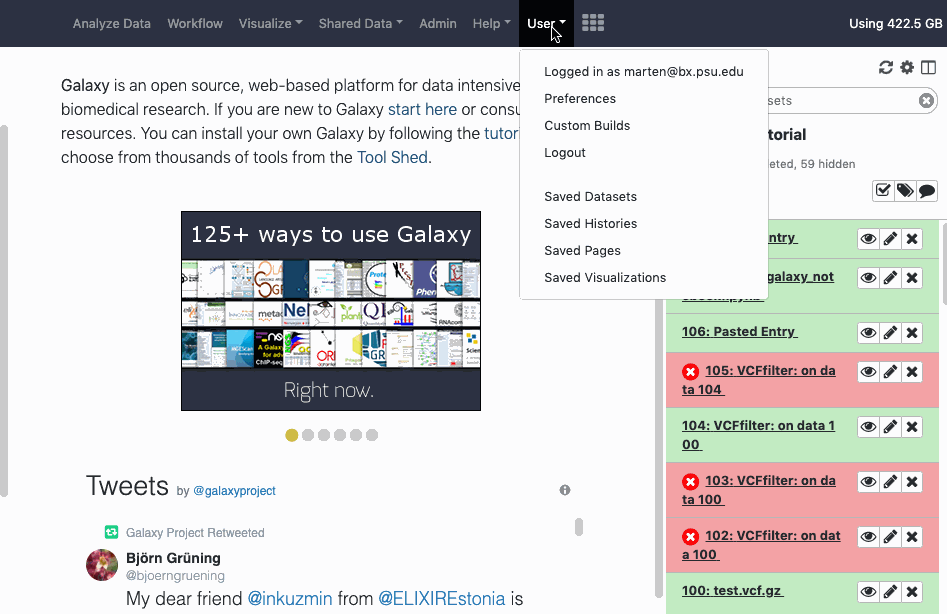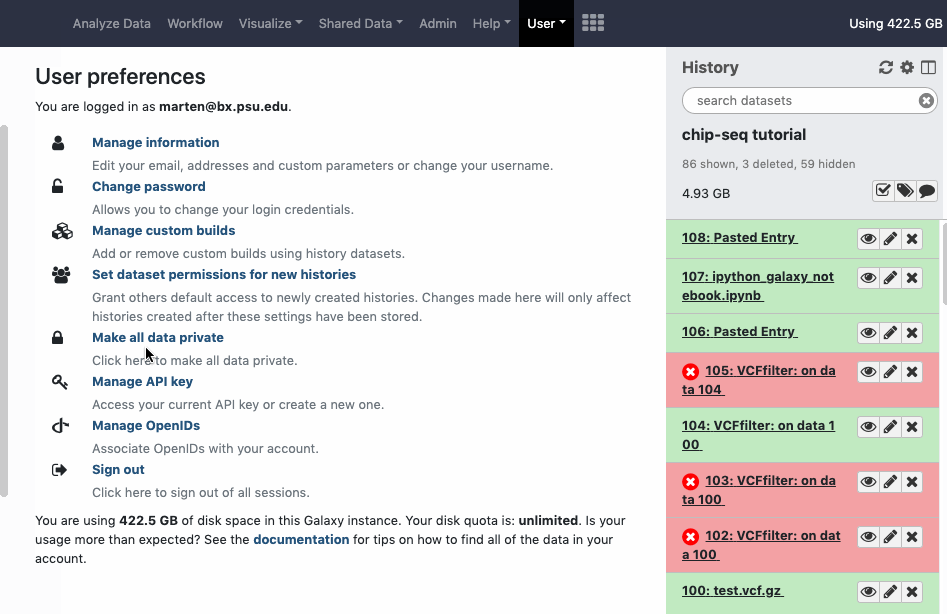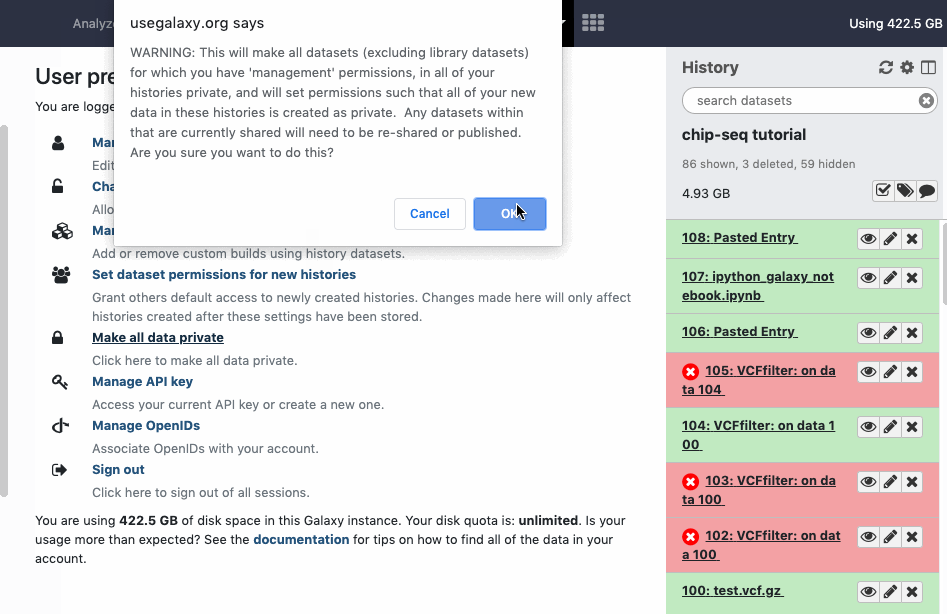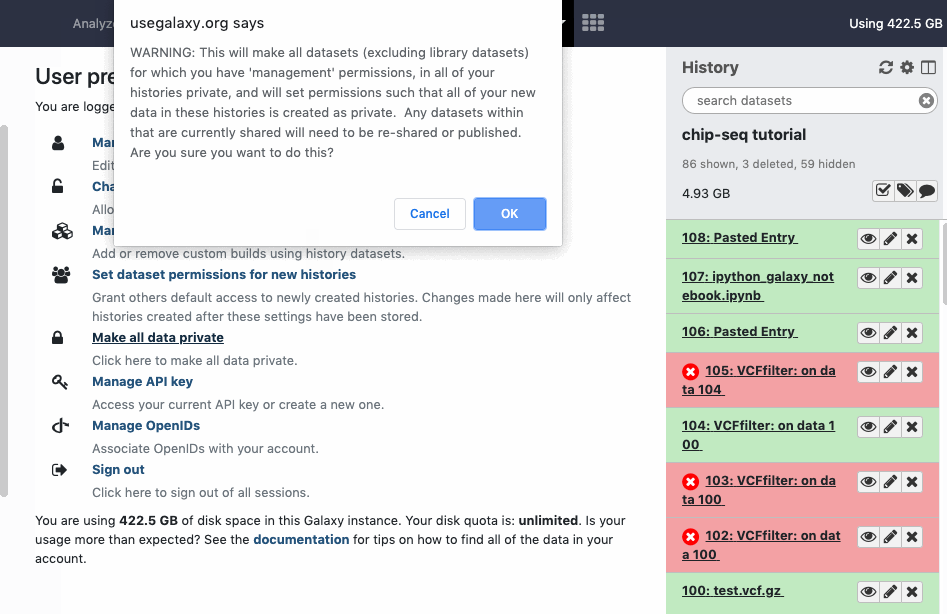
This mass option will set every dataset in every history you own private. Also new data created in all histories will be private. The option is available under ‘User - Preferences’, look for an item named ‘Make all data private’. Watch animation.
{kind=link}
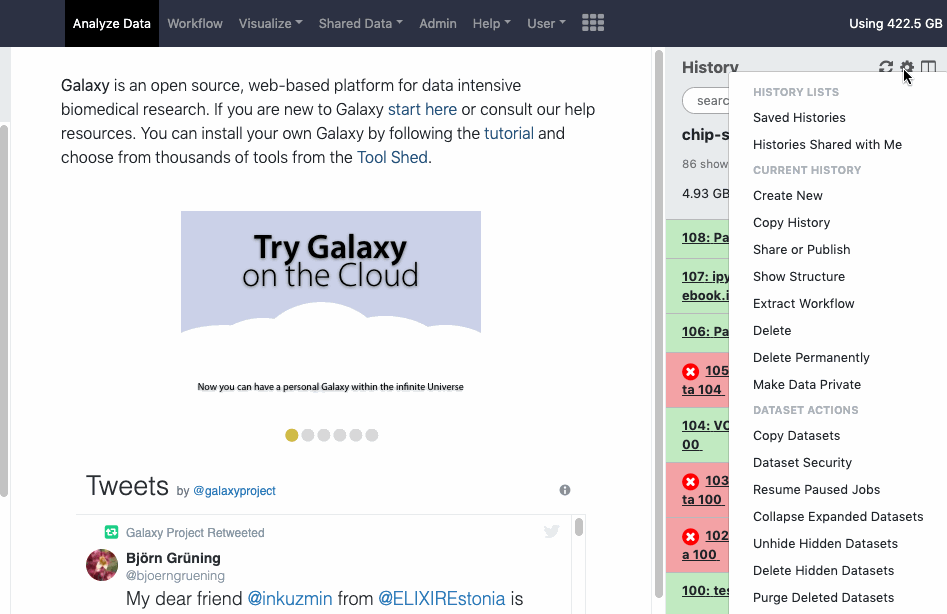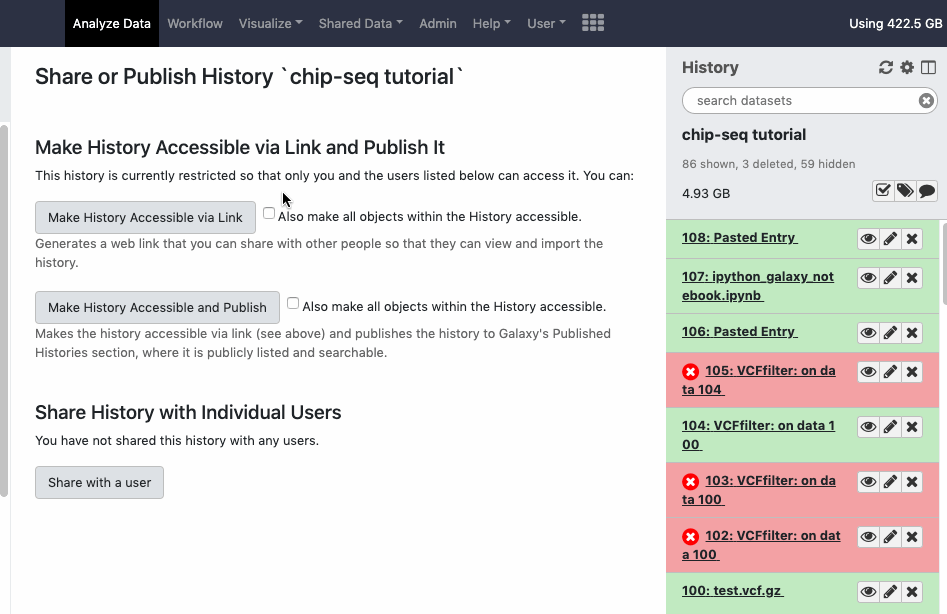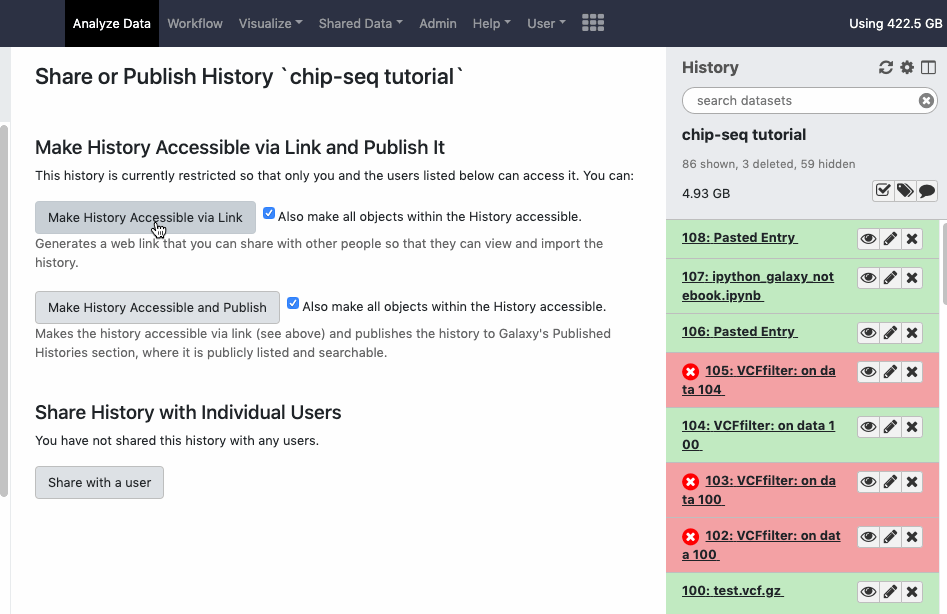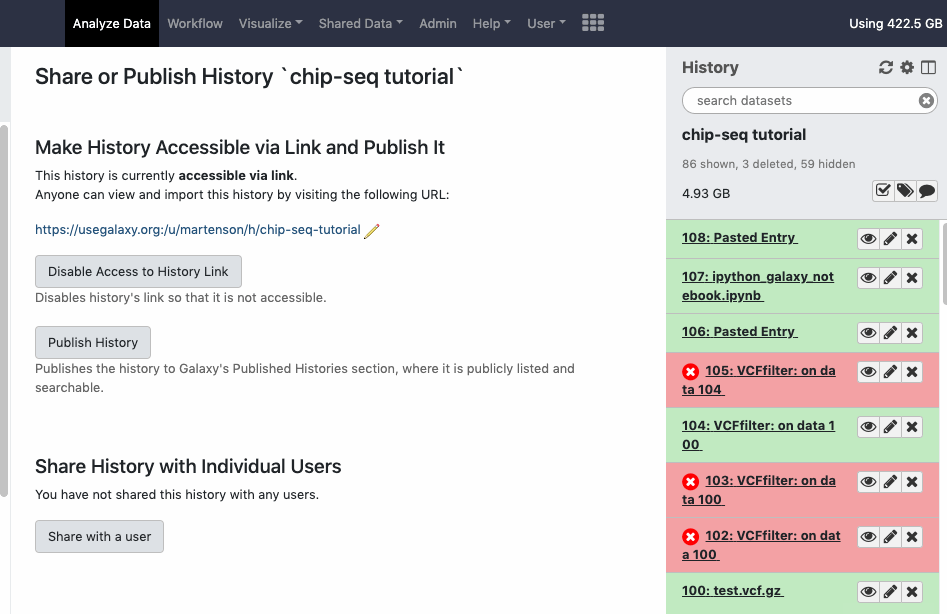
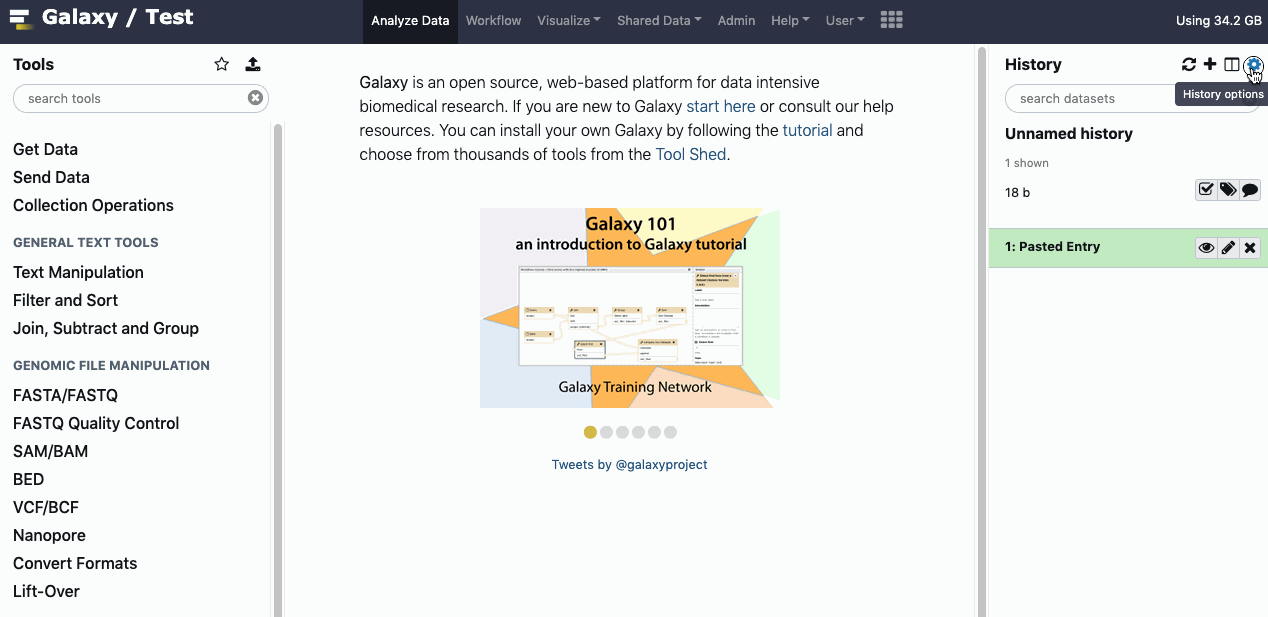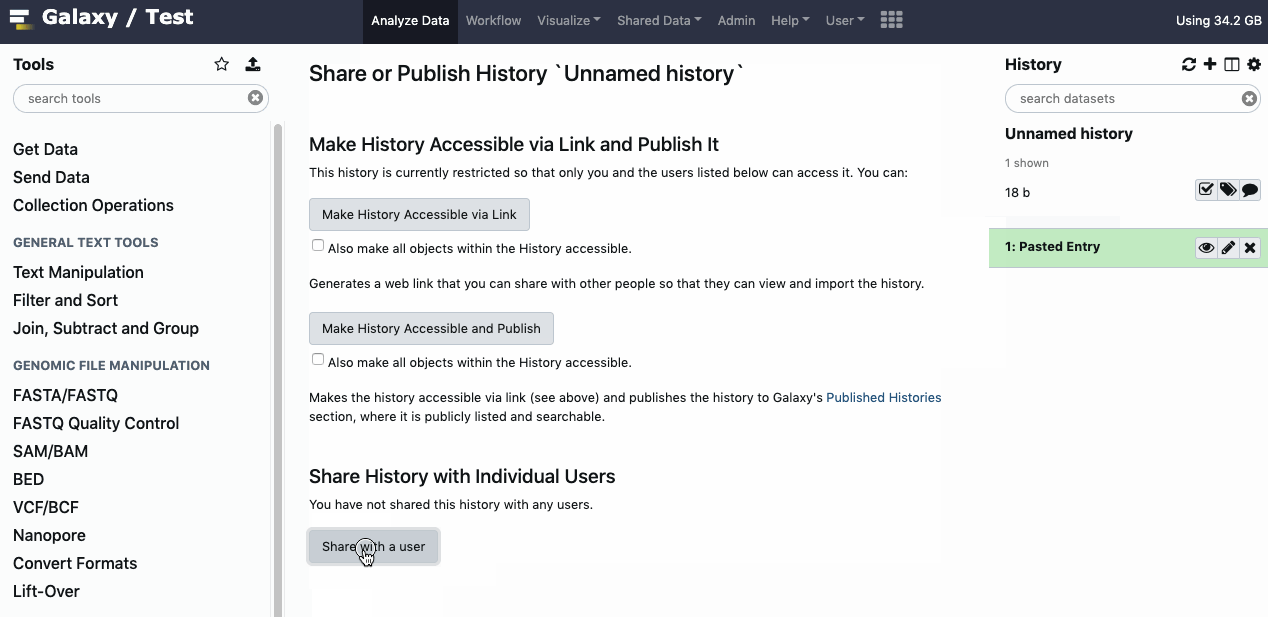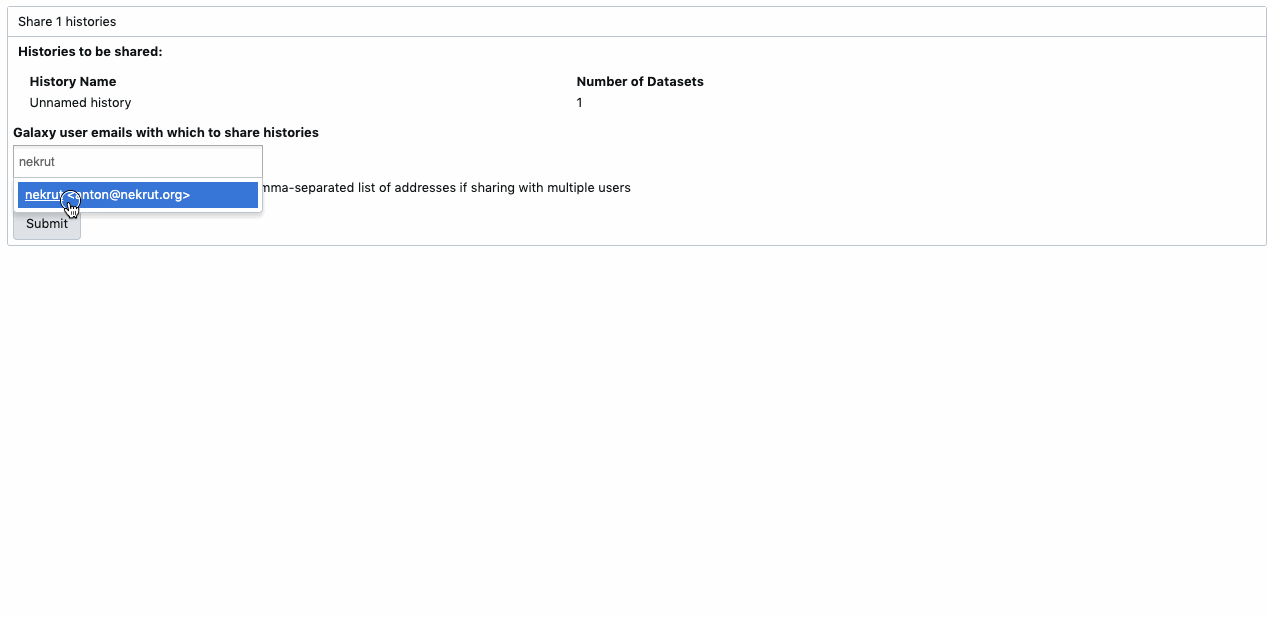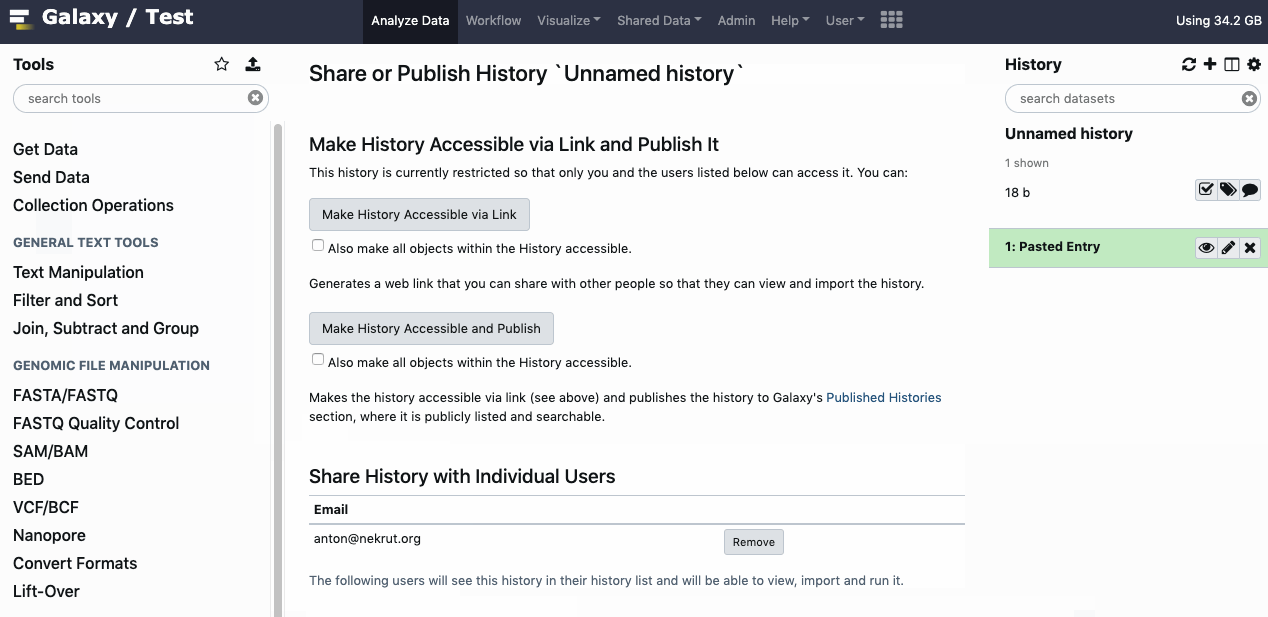
In order to share history with all its content via link you can explicitly make all datasets in the history accessible, so anybody with the link to history can see all its contents. Otherwise you share the datasets with the Galaxy users explicitly. The interface is available under the ‘cog - History options’, look for menu option ‘Share or Publish’. Watch animation.
{kind=link}
You can share history directly with a specific Galaxy user if you know their account’s email address. Only the two of you will have access to that history. The interface is available under the ‘cog - History options’, look for menu option ‘Share or Publish’. Watch animation.
{kind=link}
Permissions of datasets derived from other datasets
So far, we’ve dealt with the permissions applied to datasets created from upload and external sources. With datasets created by tools that have other datasets as inputs the situation is different.
For the ‘manage permissions’ permission, only the intersection of the input datasets’ roles are set on the output dataset. For the ‘access’ permission, the join of the input datasets’ roles are set on the output dataset:
- User A is a member of Role A and Role B
- Dataset A requires Role A to manage permissions
- Dataset A requires Role A to access
- Dataset B requires Role B to manage permissions
- Dataset B requires Role B to access
If a tool is run that uses Dataset A and Dataset B as inputs, the resulting dataset (Dataset AB) has the following permissions:
- NO Role is able to manage permissions
- Role A AND Role B are required to access
If, however the following were added to our example:
- Dataset B requires Role A to manage permissions
Then the permissions on Dataset AB would be:
- Role A is required to manage permissions
- Role A AND Role B are required to access
Important points
- Anonymous users’ data is always public (but not listed). Users must log in to access security controls.
- Every user is associated with at least 1 role, their “private” role, which is identical to their user name (email address).
- If no roles are set for the ‘access’ permission, the dataset is public, and anyone may access it given they know the url.
- If no roles are set for the ‘manage permissions’ permission, no one (other than administrators) may modify its permissions.
- Private data must be made public to be used with external sources, such as the “view at UCSC” link, or the “Perform genome analysis and prediction with EpiGRAPH” tool.