On this page
usegalaxy.org Reference Data
usegalaxy.org (Main is home to over 8 TB of reference data. This is comprised mainly of genome sequence builds and associated prebuilt indexes for the tools installed on usegalaxy.org, as well as the Galaxy-specific configuration files that make the data known to those tools. Because preparing this data for your own local Galaxy server or an external application can be a laborious process, we have made this reference available from a variety of schemes.
Data Structure
The data repository can be browsed via HTTP at http://datacache.galaxyproject.org.
There are two primary directories in the reference data repository:
- /managed: Data generated with Galaxy Data Managers, organized by data table (index format), then by genome build.
- /byhand: Data generated prior to the existence/use of Data Managers, manually curated. For legacy reasons, this directory is shared as /indexes on the HTTP and rsync servers.
These directories have somewhat different structures:
- /managed is organized by index type, then by genome build (Galaxy dbkey)
- /byhand is organzied by genome build, then by index type
Both directories contain a location subdirectory, and each of these contain a tool_data_table_conf.xml file:
Galaxy consumes these tool_data_table_conf.xml files and the .loc “location” files they reference. The paths
contained in these files are valid if the data is mounted via CVMFS.
Examples of data include:
- twoBit (
.2bit) and FASTA (.fa) sequence files - Bowtie 2 and BWA indexes
- Mutation Annotation Format (
.maf) files - SAMTools FASTA indexes (
.fai)
You can either use the data and Data Table Configuration / location files as-is (with path editing to fit your environment), or use these as models, or simply move the data into your own custom hierarchy.
In addition to the standard reference data, we also host a repository of sequences and indexes for pathogens available in Galaxy for BRC Analytics, and assemblies and indexes from the Vertebrate Genomes Project
Converting Formats
Most genome sequences in Galaxy are in both twoBit and FASTA formats. twoBit files are smaller and can be
converted to FASTA using the twoBitToFa tool available from UCSC. There are many common bioinformatics tools to that
can be used for file manipulations, but this and other related tools are in the UCSC Genome Browser source code
downloads section.
Related topics
Mounting Reference Data with CernVM-FS (CVMFS)
The usegalaxy.org reference data is housed in a CernVM-FS (CVMFS) repository that distributes the data in multiple replicas across the United States and Europe. Because of this, it is possible to directly mount the data directly on your Galaxy server. CVMFS is a caching, HTTP-based filesystem with a Linux Filesystem in Userspace (FUSE) (mount) client.
When initially mounted, CVMFS does not consume any local disk space on the client (in this case, your Galaxy server). Instead, as files are accessed, they are pulled from one of the replica (Stratum 1) servers to a local disk-based cache of a configurable size.
Currently, the Galaxy Docker Image image is preconfigured to mount this data.
CVMFS Considerations
In order to effectively use CVMFS, you should be aware that the reference data will need to be mounted on both your Galaxy server and any compute resources (i.e. cluster nodes) on which you will run jobs against that data. Mounting requires root privileges. CVMFS does provide workarounds for systems where direct mounting is not an option, these are discussed in the CernVM-FS on Supercomputers documentation.
If you are running more than a small cluster (~5 nodes) and/or are run tools that aggressively access the reference data with a very small cache, please configure at least a local proxy, if not a full Stratum 1 (replica/mirror). Overloading the public Stratum 1 servers can result in a traffic block in order to maintain service availability.
Before you begin, it is a good idea to become acquianted with the CVMFS Overview, Getting Started and Client Configuration documentation.
CVMFS Client Configuration
The CVMFS documentation is very thorough, so we do not provide step by step instructions on configuring a client, as this can be performed simply by following the Getting Started and Client Configuration documentation. Alternatively, the galaxyproject.cvmfs Ansible role can be used to quickly set up the client configuration.
If configuring by hand, once installed, you should be able to run cvmfs_config to perform the basic CVMFS setup, then
add the Galaxy-specific configuration files:
/etc/cvmfs/default.local
CVMFS_REPOSITORIES="data.galaxyproject.org"
CVMFS_HTTP_PROXY="DIRECT"
CVMFS_QUOTA_LIMIT="4000" # the cache size in MB
CVMFS_USE_GEOAPI=yes # sort server list by geographic distance from clientIf you’d also like to access the BRC Analytics and/or VGP data, you can add them to CVMFS_REPOSITORIES:
CVMFS_REPOSITORIES="data.galaxyproject.org,brc.galaxyproject.org,vgp.galaxyproject.org"/etc/cvmfs/domain.d/galaxyproject.org.conf
CVMFS_SERVER_URL="http://cvmfs1-tacc0.galaxyproject.org/cvmfs/@fqrn@;http://cvmfs1-iu0.galaxyproject.org/cvmfs/@fqrn@;http://cvmfs1-psu0.galaxyproject.org/cvmfs/@fqrn@;http://galaxy.jrc.ec.europa.eu:8008/cvmfs/@fqrn@;http://cvmfs1-mel0.gvl.org.au/cvmfs/@fqrn@"
CVMFS_KEYS_DIR="/etc/cvmfs/keys/galaxyproject.org"/etc/cvmfs/keys/galaxyproject.org/data.galaxyproject.org.pub
-----BEGIN PUBLIC KEY-----
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA5LHQuKWzcX5iBbCGsXGt
6CRi9+a9cKZG4UlX/lJukEJ+3dSxVDWJs88PSdLk+E25494oU56hB8YeVq+W8AQE
3LWx2K2ruRjEAI2o8sRgs/IbafjZ7cBuERzqj3Tn5qUIBFoKUMWMSIiWTQe2Sfnj
GzfDoswr5TTk7aH/FIXUjLnLGGCOzPtUC244IhHARzu86bWYxQJUw0/kZl5wVGcH
maSgr39h1xPst0Vx1keJ95AH0wqxPbCcyBGtF1L6HQlLidmoIDqcCQpLsGJJEoOs
NVNhhcb66OJHah5ppI1N3cZehdaKyr1XcF9eedwLFTvuiwTn6qMmttT/tHX7rcxT
owIDAQAB
-----END PUBLIC KEY-----/etc/cvmfs/keys/galaxyproject.org/galaxyproject.org.pub
The BRC and VGP repositories use a different (common) key. The singularity.galaxyproject.org
([Singularity/Apptainer][apptainer BioContainers) repository also uses this
key and the data repository will eventually transition to this key as well, so it’s not a bad idea to install it even if
you only intend to use the data repository:
-----BEGIN PUBLIC KEY-----
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAuJZTWTY3/dBfspFKifv8
TWuuT2Zzoo1cAskKpKu5gsUAyDFbZfYBEy91qbLPC3TuUm2zdPNsjCQbbq1Liufk
uNPZJ8Ubn5PR6kndwrdD13NVHZpXVml1+ooTSF5CL3x/KUkYiyRz94sAr9trVoSx
THW2buV7ADUYivX7ofCvBu5T6YngbPZNIxDB4mh7cEal/UDtxV683A/5RL4wIYvt
S5SVemmu6Yb8GkGwLGmMVLYXutuaHdMFyKzWm+qFlG5JRz4okUWERvtJ2QAJPOzL
mAG1ceyBFowj/r3iJTa+Jcif2uAmZxg+cHkZG5KzATykF82UH1ojUzREMMDcPJi2
dQIDAQAB
-----END PUBLIC KEY-----Test the Client
Once configured, you should be able to access the data with cd /cvmfs/data.galaxyproject.org. You may need to restart
AutoFS first with systemctl restart autofs (the exact command depends on your specific Linux distribution and
release).
The configuration given above is a minimum, please consult the CVMFS documentation to further tune your client.
Galaxy Configuration
In galaxy.yml, configure the paths to the tool_data_table_conf.xml files with the tool_data_table_config_path
option in the galaxy: section:
galaxy:
tool_data_table_config_path:
- /cvmfs/data.galaxyproject.org/byhand/location/tool_data_table_conf.xml
- /cvmfs/data.galaxyproject.org/managed/location/tool_data_table_conf.xml
# BRC Analytics sequences
- /cvmfs/brc.galaxyproject.org/config/tool_data_table_conf.xml
# VGP sequences
- /cvmfs/vgp.galaxyproject.org/config/tool_data_table_conf.xml
- config/tool_data_table_conf.xmlOnce your Galaxy server has been restarted, you should see the reference data in the tools that use them.
CVMFS Server Details
The list of Stratum 1 servers for the data.galaxyproject.org CVMFS repository currently include:
| Server | Host | Location |
|---|---|---|
cvmfs1-psu0.galaxyproject.org | Galaxy Project | Penn State University, Pennsylvania, USA |
cvmfs1-iu0.galaxyproject.org | Galaxy Project via ACCESS | Jetstream Cloud at Indiana University, Indiana, USA |
cvmfs1-tacc0.galaxyproject.org | Galaxy Project | Texas Advanced Computing Center, University of Texas at Austin, Texas, USA |
cvmfs1-mel0.gvl.org.au | Galaxy Australia | Melbourne, Australia |
cvmfs1-ufr0.galaxyproject.eu | Galaxy Europe | Freiburg, Germany |
The full path to the repository, e.g. for use in the CVMFS_SERVER_URL configuration parameter, where <SERVER:[PORT]>
is one of the servers above and <REPO> is the CVMFS repo name, is:
http://<SERVER:[PORT]>/cvmfs/<REPO>The reference data repo name is data.galaxyproject.org, but for use in CVMFS_SERVER_URL, you should use @fqrn, as
CVMFS templates the repository name in to the URL for you.
Obtaining Reference Data with Rsync or HTTP
In addition to directly mounting the data, it can be fetched with Rsync or over the web using HTTP. Rsync is a particularly useful tool for this as it is able to both recursively retrieve data, as well as skip data that is already present on the local side that has not changed.
The Rsync Data Manager also fetches data from the reference data rsync server.
The rsync command line tool is often preinstalled on many popular Linux distributions, but if it is not available, it
can be intalled via the system package manager, usually with the package name rsync. Consult your distribution’s
documentation for help.
Rysnc Server Name
datacache.galaxyproject.orgExample Data Retrieval
To download the complete directory for the phiX genome:
$ rsync -avzP rsync://datacache.galaxyproject.org/indexes/phiX .Note the use of the -z flag, which compresses/decompresses data on the fly. This is not crucial for a small genome
such as phiX, but significantly improves network performance for larger genomes. The additional flags are explained on
in the documentation (accessible locally with man rsync).
The final argument of . means that the data will be transferred to your current directory. You can replace . with a
path to control where the data is downloaded to:
$ rsync -avzP rsync://datacache.galaxyproject.org/indexes/phiX /data/genomesMost of the baterical genomes are nested one directory down in
/indexes/microbes. Thus, to fetch the sequence and indexes for a
microbe, use a command like the following, where 63 is the assigned dbkey for the NCBI genome accession
NC_007622, sourced from UCSC, and listed under GUI Genome Builds as Staphyloccus aureus RF122 (63). For any
genome, the dbkey is the value (inside_here) of its UCSC name.
$ rsync -avzP rsync://datacache.galaxyproject.org/indexes/microbes/63 .Organization and DBKEY
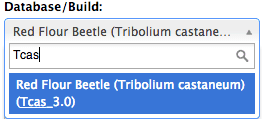
Genomes are organized in directories by reference genome dbkey. If you are not sure of the dbkey, it can be found in the Main user interface. This value is what is populated into the “database” attribute for a dataset. Or, it is the last value in parenthesis (dbkey) at the end of the full reference genome build name in two specific places in the usegalaxy.org interface:
Example: dbkey ‘Tcas_3.0’
- On Get Data -> Upload File tool:

- Under Edit Attributes (found by clicking on any dataset’s upper right corner pencil icon):
Location (*.loc) Files
To retrieve an exact copy of the .loc files used by the tools on usegalaxy.org, execute these rsync commands:
$ rsync -avzP rsync://datacache.galaxyproject.org/indexes/location/ location/byhand
$ rsync -avzP rsync://datacache.galaxyproject.org/managed/location/ location/managed